There have been significant advancements in genome sequencing technologies since the completion of the Human Genome Project in 2003. The field has made remarkable progress in improving the speed, accuracy, and cost-effectiveness of DNA sequencing. This has led to the development of new and innovative sequencing technologies that have greatly expanded our ability to sequence and analyze genomes. These advancements have paved the way for many discoveries in genetics and genomics and have helped to make genome sequencing a more routine and accessible tool for researchers and clinicians alike.
Benefits
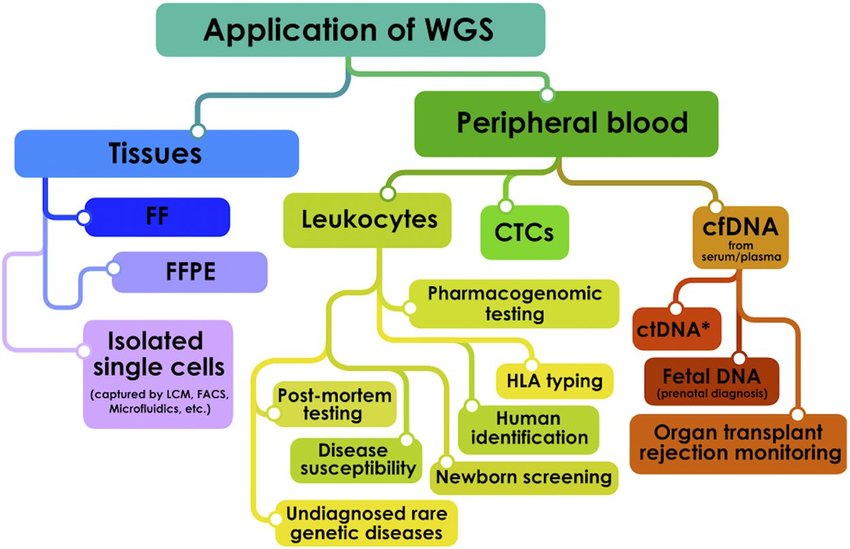
The major benefit of Whole Genome Sequencing (WGS) is that it enables a comprehensive analysis of an individual’s entire genome. With this approach, all the variations in the genome, ranging from small nucleotide changes to larger copy number variations and translocations, can be identified in a single test. This makes WGS a powerful tool for studying the genetic basis of various diseases and conditions. By examining the entire genome, researchers can gain a more complete understanding of the genetic factors contributing to a particular disease or trait, which can lead to better diagnosis, treatment, and management options.
Whole genome sequencing is a valuable tool that can help identify the genetic basis of both monogenic and polygenic diseases. For monogenic diseases like thalassemia, WGS can pinpoint specific genetic variants causing the disease. Meanwhile, for polygenic diseases like type 2 diabetes mellitus, WGS can identify genetic variants contributing to the disease risk. With this information, personalized prevention and management strategies can be developed for individuals at increased risk.
The cost of sequencing the first-ever genome was 2.7 billion US dollars, which was prohibitively expensive for most applications. However, with the development of next-generation sequencing (NGS) technologies, the cost of sequencing has continued to decrease dramatically. Currently, the cost of sequencing a genome is around a few thousand dollars, but it is expected to fall below $1,000 per genome soon. This cost reduction has made genome sequencing more accessible for research and clinical applications. As sequencing costs continue to decline, it is anticipated that it will become a routine tool in personalized medicine, disease diagnosis, and prevention.
While not yet widely adopted in clinical practice, the use of whole genome sequencing (WGS) in cancer research could be highly beneficial. By analyzing the entire genome of cancer cells, researchers may be able to identify the specific genetic drivers of tumors. This information could help to develop new biological therapies that target these drivers and improve treatment outcomes for cancer patients. As WGS technologies continue to advance, they may become a more routine tool for cancer diagnosis and treatment.
Development of these new devices not only solved efficiency and resolution drawbacks but also increased sequencing data amount tens of times higher than first sequencing systems and decreased the costs per reaction.
Sequencing GC-rich regions has long been a challenge due to the formation of secondary structures that can impede sequencing accuracy. To address this difficulty, scientists have employed the use of single-strand binding proteins (SSB) to aid in the sequencing process. SSB helps to prevent the formation of secondary structures, allowing for more accurate sequencing of GC-rich regions. Despite this improvement, GC-rich regions can still present challenges in sequencing, and ongoing research continues to explore new techniques and technologies to improve accuracy and efficiency in these areas.
Limitations
A significant challenge associated with WGS is the vast amount of data generated, which requires extensive analysis and interpretation. Despite growing knowledge in genomics, many genes still have unknown roles, and a large number of genomic variants have not been identified as benign or pathogenic. This means that while WGS produces a large volume of data, much of it may be irrelevant or misleading. As a result, careful consideration and interpretation of the data are necessary to avoid errors and misinterpretations that could impact diagnosis and treatment decisions. Ongoing research and technological advancements are continually improving our ability to accurately interpret and utilize WGS data.
Storing the large amount of data generated by WGS poses challenges related to capacity, cost, and privacy concerns, including potential ethical dilemmas with insurance companies and family members.
DNA contamination from other organisms is a significant concern for any sequencing project, including those that use Sanger sequencing. It is important to carefully manage and monitor potential sources of contamination to ensure accurate and reliable results.
Using a de novo sequence assembly algorithm for WGS can result in collapsed identical repeats, leading to a reduction or loss of genomic complexity.
The YH de novo assembly contains duplications that are likely false, as they were not consistent with duplications predicted by read depth or detected by array comparative genomic hybridization analysis. Specifically, 95.6% of these duplications are believed to be inaccurate.
Biases against duplications and repeats, as well as fragmentation, can lead to concerns regarding the accuracy and completeness of genome assemblies, including the panda genome. It is important to carefully consider and account for these factors when interpreting sequencing data and making inferences about genomic structure and function.
References
- Naidoo N, Pawitan Y, Soong R, Cooper DN, Ku C-S. Human genetics and genomics a decade after the release of the draft sequence of the human genome. Hum Genomics. 2011;5: 577–622.
- Wrzeszczynski KO, Felice V, Shah M, et al (2018) Whole genome sequencing-based discovery of structural variants in glioblastoma. In: Placantonakis aspartic acid, Glioblastoma. Methods in molecular biology, vol 1741. Humana Press, New York, NY, pp 1–29.
- Katsanis SH, Katsanis N. Molecular genetic testing and the future of clinical genomics. Nat Rev Genet, 2013; 14(6):415-26.
- Radford C, Prince A, Lewis K, et al. Factors that impact the delivery of genetic risk assessment services focused on inherited cancer genomics: expanding the role and reach of certified genetics professionals. Journal of Genetic Counseling, 2013; 23(4):522-530.
- Zhao EY, Jones M, Jones SJM. Whole-genome sequencing in cancer. Cold Spring Harb Perspect Med, 2019; 9(3):a034579.
- Metzker ML (2010) Sequencing technologies—the next generation. Nat Rev Genetics 11(1):31-46
- Ronaghi M, Karamohamed S, Pettersson B, Uhlén M, Nyrén P (1996) Real-time DNA sequencing
- using detection of pyrophosphate release. Anal Biochem 242(1):84-89.Botkin JR, Rothwell glutamic acid, “Whole genome sequencing and newborn screening”, Curr Genet Med Rep, 2016; 4(1):1–6.
- Howard HC, Knoppers BM, et al., “Whole-genome sequencing in newborn screening? A statement on the continued importance of targeted approaches in newborn screening programs”, Eur J Hum Genet, 2015; 23(12):1593–1600.
- Zhang Z, Schwartz S, Wagner L, Miller W. A greedy, “Algorithm for aligning DNA sequences”, Comput. Biol. 2000; 7:203–214. [PubMed: 10890397]
- Green P., “Whole-genome disassembly”, Proc. Natl. Acad. Sci. USA. 2002; 99:4143–4144. [PubMed:11904394]
- Alkan C, et al. “Personalized copy number and segmental duplication maps using next-generation sequencing”. Nat. Genet. 2009; 41:1061–1067. [PubMed: 19718026]
- Worley KC, Gibbs RA. Genetics: decoding a national treasure. Nature. 2010; 463:303–304. [PubMed: 20090741]