Recent Articles

What Are Recombinant Proteins?
Early lab work often presents a challenge: researchers need reliable protein targets without the variability that comes from…
Read more
ELISA Sensitivity and Specificity
Sensitivity reflects a test’s ability to correctly identify individuals with a disease or condition, while…
Read more
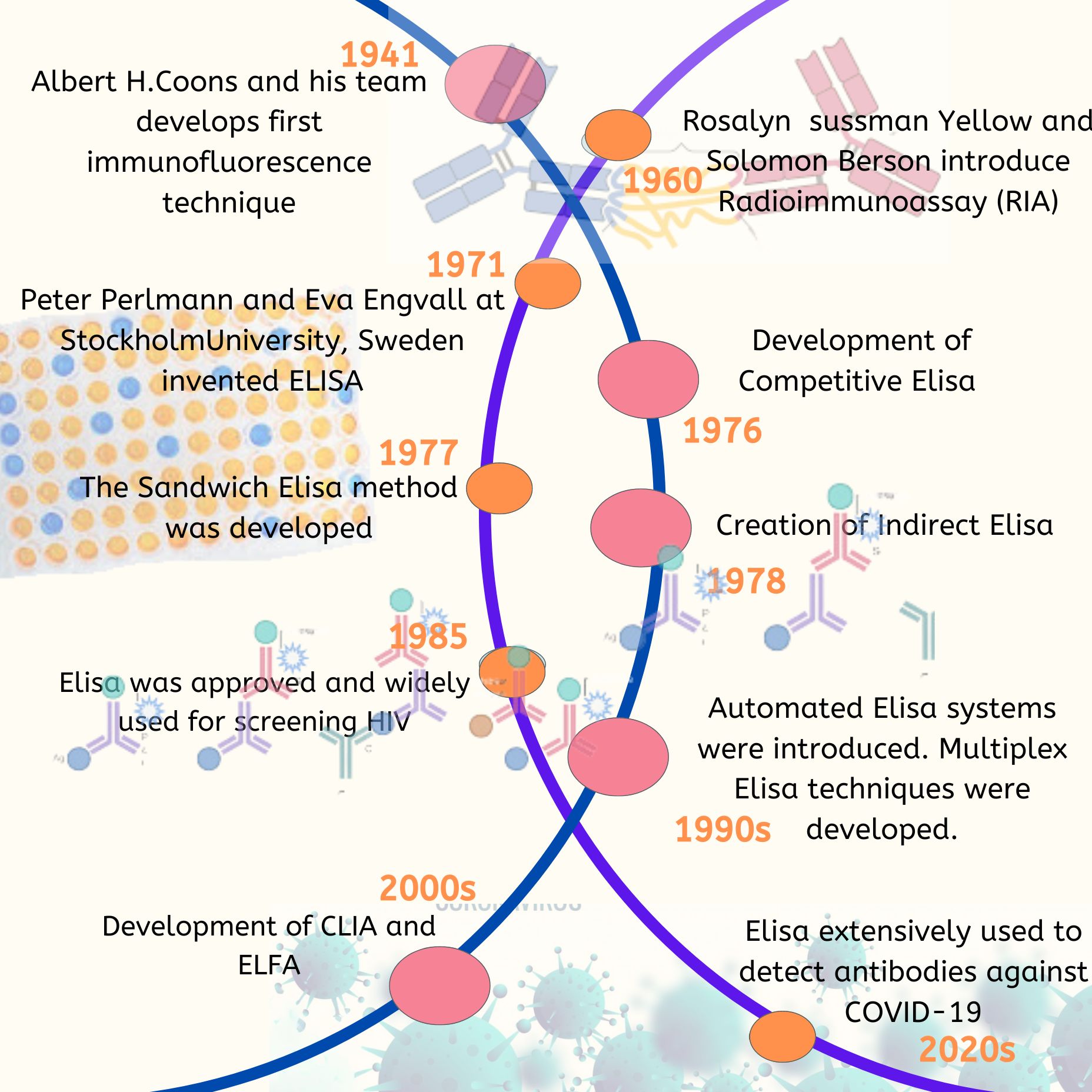
ELISA Evolution
Key Milestones 1941 – Introduction of Immunofluorescence In 1941, Albert H. Coons and his team were the first…
Read more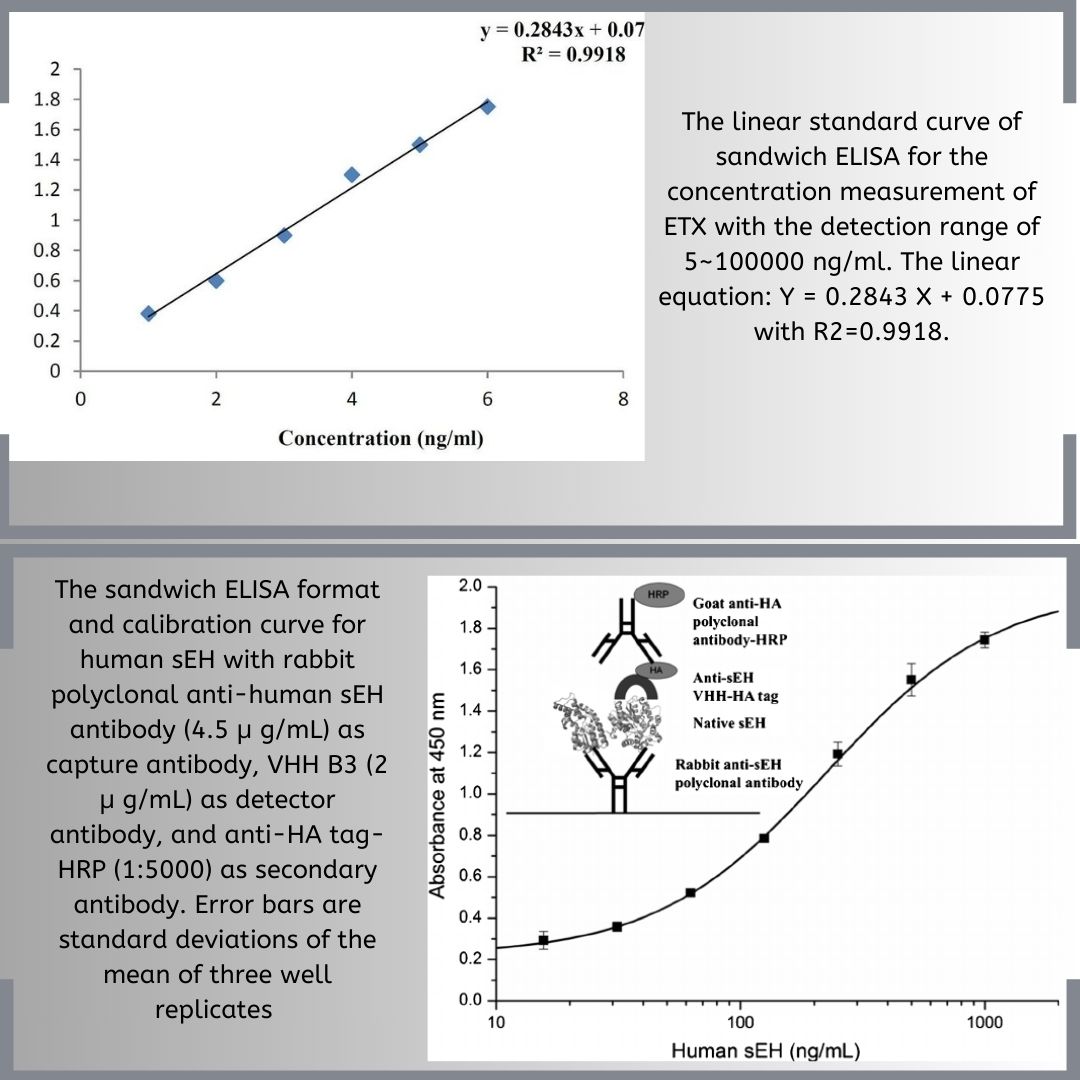
ELISA: Data Analysis and Interpretation
How to Analyze ELISA: 1. Run samples in duplicates or triplicates to ensure statistical accuracy. Average the readings…
Read morePopular Posts
No posts found.